Within roughly the same six-month window, Anthropic shipped Agent Teams for Claude Code, OpenAI published Swarm and the production-ready Agents SDK, Cursor announced multi-agent subagents, and the open source community released Claude-Flow, a Cline fork that pushes agent counts past sixty. Every serious AI coding tool arrived at roughly the same architectural conclusion at about the same time: single agents were no longer enough.

That convergence created a new problem. AI agent users now face several meaningfully different coordination models, including leader-worker hierarchies, hive-mind swarms, handoff chains, and IDE-integrated multi-model pipelines. Every framework benchmarks itself favorably against abstract workloads. None benchmark against one another on the same real engineering task.
That’s what this article does. Five implementations, one task, real numbers, and a decision framework for determining which coordination model is actually appropriate before you’ve already burned the tokens finding out the hard way.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
The test task is a medium-complexity full-stack feature: a JWT-based authentication module with user registration, login, and token refresh endpoints, middleware for protected routes, integration tests, and an OpenAPI documentation file. It was intentionally chosen because it is plausibly parallelizable. Backend endpoints, route protection, and tests can be separated, but not so cleanly that coordination becomes trivial.
All five implementations ran against the same task description, the same codebase scaffold, and the same model where applicable (claude-sonnet-4-6 for Anthropic-based tools, gpt-4o for OpenAI Swarm). Five metrics were tracked across every implementation:
| Metric | What was measured |
|---|---|
| Wall-clock time | Start of first prompt to last accepted output |
| Token cost | Total input + output tokens, converted to USD |
| Coordination overhead | Merge conflicts, handoff latency, redundant work |
| Code quality | Test coverage percentage + ESLint score |
| Human intervention | Number of manual corrections during the run |

Here are the execution commands for all five tools, exactly as they operate right now.
Solo Claude Code (baseline)
Solo Claude Code is the control group: one agent, one context window, and sequential execution. To keep the metrics clean and remove human latency from the run, the agent operated in headless mode (--dangerously-skip-permissions), giving it full autonomy to write files and execute tests without interactive prompts.

# Headless autonomous execution /usr/bin/time -v claude -p "Build a JWT auth module with registration, login, and token refresh endpoints, route protection middleware, integration tests, and OpenAPI docs. Use Express and the existing scaffold in ./src." \ --dangerously-skip-permissions --output-format json
// Parsed execution metrics
{
"subtype": "success",
"num_turns": 123,
"result": "All 61 tests pass and TypeScript is clean...",
"permission_denials": [],
"usage": { "cache_read_input_tokens": 9840283, "output_tokens": 73109 }
}
Total time: 29m 50s | Tokens: ~9.9M in / 73.1k out | Cost: $7.71
The solo model was highly resilient, but bottlenecked by its linear execution pattern. Over 123 turns, it successfully built the module, fixed pre-existing type bugs, and passed 61 tests. Because a single agent held the full context, shared interfaces matched perfectly and coordination overhead was effectively zero. However, that sequential execution pushed wall-clock time to nearly 30 minutes and drove up token cost ($7.71) through heavy prompt caching. It sets a strong reliability baseline, but leaves a large time window for parallel orchestration to beat.
Anthropic Agent Teams (leader-worker)
Agent Teams is an experimental native feature enabled via CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1. Unlike standard CLI execution, this mode orchestrates a true leader-worker architecture, spinning up isolated context windows for each spawned agent and coordinating them through a shared task queue.
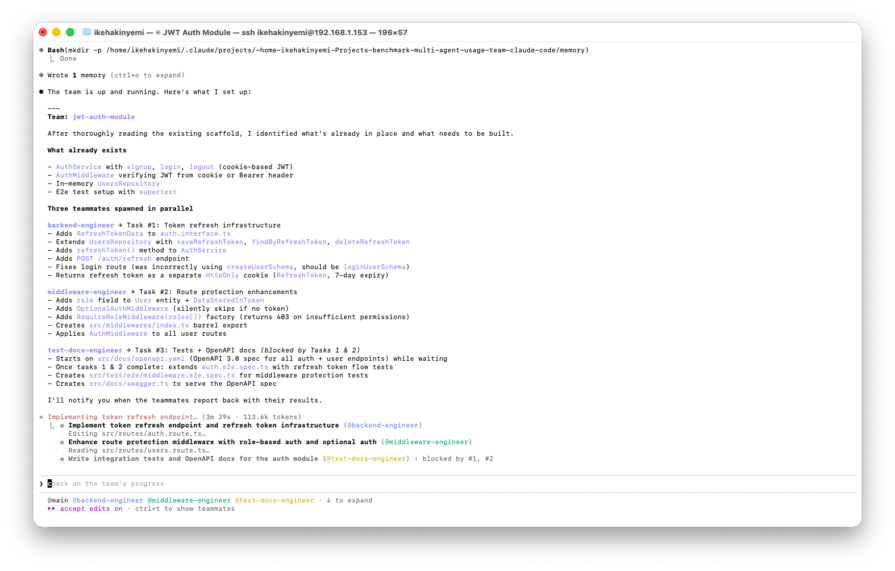
Launch Claude interactive mode and paste the prompt below:
"Create an agent team to build a JWT auth module with registration, login, token refresh endpoints, route protection middleware, integration tests, and OpenAPI docs. Use Express and the existing scaffold in ./src. Spawn three teammates: one for backend endpoints, one for route protection middleware, and one for integration tests and docs. Have them coordinate through the shared task list."
Total time: 16m 05s | Context bloat: ~59k tokens | Workers spawned: 3/3 | Tests: 18 passing | Cost: ~$1.99 (API equivalent)
This implementation successfully broke through the sequential bottleneck of the baseline run, cutting wall-clock time nearly in half, from 30 minutes to 16. By parallelizing backend and middleware development, the orchestrator minimized idle time. The framework’s native task dependency management also worked as intended: @test-docs-engineer stayed blocked until the upstream agents reported completion, which meant tests were written against the final architecture rather than a moving target. Because the workers operated in tightly scoped context windows of roughly 59k tokens, instead of dragging one massive context through every turn, the estimated API cost dropped by more than 70 percent compared to the baseline.
Claude-Flow (hive-mind swarm)
Claude-Flow wraps Claude Code in a hive-mind orchestration layer, requiring explicit infrastructure setup before execution: topology selection, consensus algorithm, and memory initialization via claude-flow hive-mind init, followed by task spawning with claude-flow hive-mind spawn --claude.
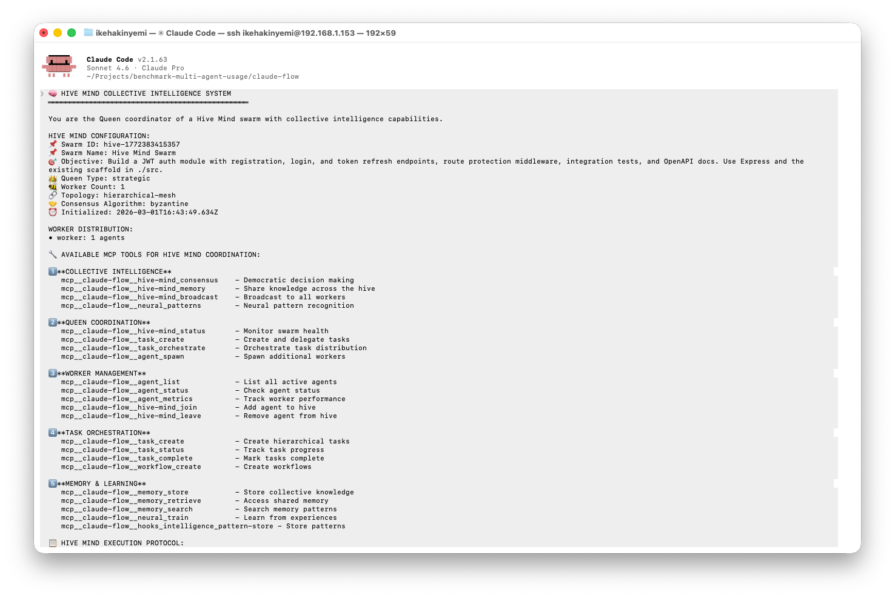
claude-flow hive-mind init # Hierarchical Mesh + Raft claude-flow memory init /usr/bin/time -v -o time_metrics_claudeflow.txt \ claude-flow hive-mind spawn \ "Build a JWT auth module with registration, login, and token refresh endpoints, \ route protection middleware, integration tests, and OpenAPI docs. \ Use Express and the existing scaffold in ./src." \ --queen-type strategic --max-agents 10 --claude
Total time: ~38m | Workers spawned: 1/10 | Tests: 63 passing | Cost: $0.45–$0.60 (API equivalent)
Despite requesting 10 workers, only the Queen agent actually executed, and the advertised swarm parallelism never materialized. In practice, what ran was a single Claude Code session with an elaborate coordination prompt injected at startup. Output quality was high, with 63 tests, clean TypeScript, full OpenAPI docs, and zero human interventions, but the result was functionally indistinguishable from a well-prompted solo run. Claude-Flow’s alpha-stage instability is the real story here, not the orchestration model itself.
OpenAI Agents SDK (sequential handoff chain)
The OpenAI Agents SDK, released in March 2025 as the production successor to the deprecated Swarm, coordinates agents through sequential handoffs. Once one agent transfers control, it exits the loop and the receiving agent owns execution from that point forward. There are no parallel workers and no shared inbox. The orchestration logic lives entirely in a Python script, since the SDK does not expose a CLI entry point. See the full script at this gist.
pip install openai-agents export OPENAI_API_KEY=sk-... /usr/bin/time -v -o time_metrics_agents_sdk.txt python agents_run.py
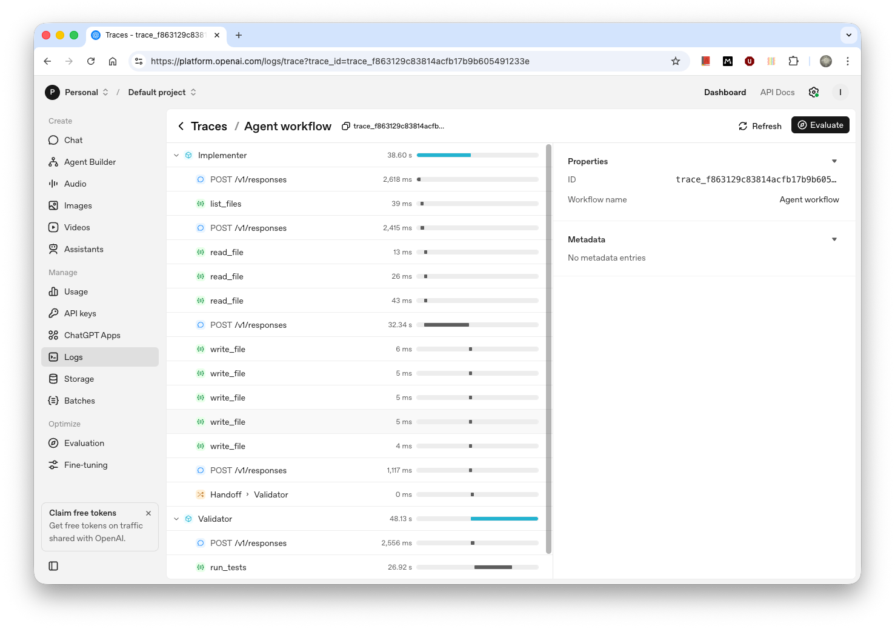
Wall-clock: 1m 30s | Input: 24.7K tokens | Output: 3.6K tokens | Cost: $0.009 | Tests: 0/5 suites passing
The handoff itself fired with effectively no latency. The Implementer read the scaffold, wrote five files, then transferred control to the Validator, which ran Jest and reported the results. No human intervention was required at any point. But the result was still five failed suites and zero passing tests.
The Implementer missed setup.ts while scanning the scaffold. That file expected a named import (import { AuthRoute } from "@routes/auth.route"), but the Implementer wrote a default export instead, which caused compilation to fail before a single test could run. The code was not wrong in isolation. The agent simply did not read enough of the codebase before committing output. Sequential handoff chains have no built-in mechanism to catch that kind of interface mismatch before work lands.
Cursor subagents
Cursor’s subagent system, shipped in v2.4 in January 2026, lets the main agent delegate discrete work to specialist agents running in parallel with isolated context windows. Subagents are defined as markdown files with YAML frontmatter stored in .cursor/agents/ and invoked automatically when the main agent determines they are relevant to the task.
mkdir -p .cursor/agents # implementer.md, tester.md, documenter.md — full config at this gist link
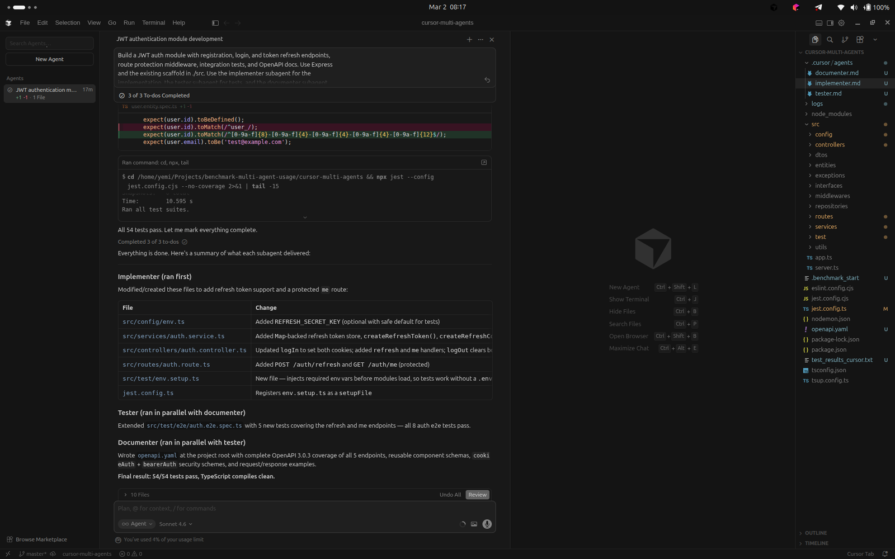
Wall-clock: ~12m | Tokens: 2.11M (104K + 338K + 1.2M + 470K) | Cost: $1.50 (included in Pro Trial) | Tests: 54/54 passing | Workers spawned: 3/3
The orchestration worked exactly as designed. The main agent explored the scaffold, identified what was missing, a token refresh endpoint, a protected route, integration tests for both, and OpenAPI docs, then created a three-step plan. Implementer ran first and completed its work sequentially. Tester and Documenter then ran in parallel.
Implementer added refresh token support with a Map-backed store, wired POST /auth/refresh and GET /auth/me using Express routing, and registered env.setup.ts as a Jest setupFiles entry so tests could run without a .env file. Tester extended the existing end-to-end suite with five new tests covering the refresh and /me endpoints, and all eight auth e2e tests passed. Documenter produced a complete openapi.yaml at the project root with OpenAPI 3.0.3 coverage for all five endpoints, reusable component schemas, and both cookieAuth and bearerAuth security schemes.
Token consumption was the highest in the benchmark at 2.11M tokens across four API calls, reflecting the cost of parallel context isolation. Each subagent had to bootstrap its own context from scratch rather than inherit a shared working window.
Five implementations, one task, one scaffold. Here’s what the numbers say:
| Implementation | Wall-clock | Tokens | Cost | Tests passing | Human interventions |
|---|---|---|---|---|---|
| Solo Claude Code | 29m 50s | ~9.97M | $7.71 | 61/61 | 0 |
| Anthropic Agent Teams | 16m 05s | ~59K ctx | ~$1.99 | 18/18 | 0 |
| Claude-Flow | ~38m | ~200K | ~$0.50 | 63/63 | 0 |
| OpenAI Agents SDK | 1m 30s | ~28.3K | $0.009 | 0/5 suites | 0 |
| Cursor subagents | ~12m | ~2.11M | ~$1.50 | 54/54 | 0 |
Cursor delivered the clearest win: 12 minutes, 54 tests passing, zero interventions, with Tester and Documenter running in parallel after Implementer completed. Agent Teams cut wall-clock time nearly in half versus solo, while reducing token cost by roughly 70 percent. Claude-Flow produced 63 passing tests, but no actual parallelism.
The Agents SDK run was the fastest and cheapest at $0.009 and 90 seconds, but produced zero passing tests. If an agent does not read enough of the codebase before committing output, interface breakage is inevitable no matter how clean the orchestration model looks on paper. That broader pattern also mirrors a larger shift in AI-assisted development, where generation gets faster but review and verification become the real bottleneck, as we explored in Why AI coding tools shift the real bottleneck to review. Solo Claude Code remains the reliability baseline: 61 tests, perfect type consistency, $7.71, and 30 minutes.
Multi-agent wins when agents share enough codebase context to align on interfaces before work begins, and when parallelism genuinely materializes. When neither condition holds, solo is often faster, cheaper, and more correct.
The key coordination primitive in multi-agent systems is not “use more agents.” It is “use more agents only when the task can be cleanly divided and the agents can agree on interfaces before work begins.”
Every framework here can orchestrate agents. What separates the results is whether the orchestration layer has enough codebase context to prevent conflicting assumptions. When that condition holds, multi-agent can be faster, cheaper, and more capable. When it doesn’t, you are paying coordination overhead for solo-agent performance.
That tradeoff also sits inside the broader reality of where AI-assisted coding accelerates development, and where it doesn’t. Parallelism is not free. It has to be earned.

Learn about TypeScript v6’s breaking changes, new ES2025 features, and deprecated options. A complete migration guide from v5 to prepare for v7.

Learn how Vite+ unifies Vite, Vitest, Oxlint, Oxfmt, Rolldown, and Node.js management in one CLI.

AI companies are buying developer tools as coding agents turn runtimes, package managers, and linters into strategic infrastructure.

Learn how AI-assisted development governance uses rules, agents, hooks, and protocols to help AI coding tools produce safer, more consistent code.
Would you be interested in joining LogRocket's developer community?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

