Most AI architectures today are designed around a single assumption: a powerful, hosted large language model is always available. In practice, this assumption breaks down quickly in enterprise environments, where privacy regulations, data locality requirements, and network constraints make it impossible or unacceptable to send internal data to external services. The ideas we discuss here continue the approaches described in previous articles: Implementing local-first agentic AI: A practical guide and How to build agentic AI when your data can’t leave the network.

At the same time, not every AI-powered system needs the full expressive power of a large language model. Many internal workflows revolve around understanding intent, retrieving information from private documents, reasoning over constrained context, and producing structured outputs rather than fluent prose.
This article explores how a fully local architecture based on small language models (SLMs) and local retrieval-augmented generation (RAG) can address these needs. Starting from a concrete enterprise use case, we derive an architecture that is privacy-preserving by design, operationally realistic, and achievable today with open-source tooling and modest on-premise compute.
The working example for the use case described below is available on GitHub.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Consider an enterprise operating under strict regulatory and data-protection constraints, such as the GDPR. Internal technical documentation, incident reports, configuration files, and operational logs are classified as sensitive data and are not allowed to leave the corporate network. Outbound API calls carrying such data to third-party services are explicitly prohibited by policy.
Teams still want AI assistance to support internal workflows:
Crucially, these tasks require retrieval and reasoning over confidential data, not open-ended text generation or creative writing. In many cases, the final output is not even natural language, but a structured response consumed by another system.
A hosted LLM with RAG is therefore not a viable option: even if retrieval happens locally, the prompt and synthesized context would still be sent to the cloud. A single large on-premise LLM is also an awkward fit, as it is expensive to operate, difficult to scale, and unnecessarily powerful for the majority of requests.
This use case naturally leads to a different question:
What does an AI system look like when data locality is a hard constraint rather than an afterthought?
Once the constraints are made explicit, the solution space narrows considerably.
Retrieval-augmented generation already limits the problem by constraining the model’s input to a small, relevant subset of documents. This dramatically reduces the need for large generative capacity. What matters instead is:
These characteristics align well with the strengths of small language models. Empirical evaluations show that while sub-1B models are weak general reasoners, they perform well on classification tasks, and 1–3B models can handle structured reasoning effectively when the problem space is constrained. In a RAG setup, hallucination risk is already reduced, and expressivity is secondary to correctness.
A fully local SLM + RAG architecture, therefore, becomes not a compromise, but a direct response to the actual requirements of the system.
The architecture follows a simple principle: separate concerns and match each one to the smallest model capable of handling it reliably.
At a high level, the system consists of:
A sub-1B SLM classifies the incoming request (e.g., documentation query, incident analysis, action request) and determines whether retrieval or reasoning is required.
Private documents are embedded and stored in a local vector database. All retrieval happens within the enterprise boundary; raw documents never leave the system.
A 1–3B SLM consumes the retrieved context and performs task-specific reasoning: summarizing procedures, answering scoped questions, or producing structured outputs grounded in the source material.
Outputs can be validated, transformed into JSON or API calls, or reformatted for downstream systems. Natural language polish is optional and often unnecessary.
At no point does sensitive data leave the local environment. The cloud, if used at all, is relegated to non-critical post-processing on sanitized outputs, and can be removed entirely without breaking the system.
One advantage of this approach is that it lends itself to a repeatable implementation pattern. Hardware requirements are modest: these models can run on commodity GPUs or even CPU-only setups with acceptable latency, making them suitable for on-premise deployment or edge environments.
Because each component is narrowly scoped, the system is easier to audit, easier to debug, and cheaper to operate than a monolithic LLM-centric design.
This solution implements a local Retrieval-Augmented Generation (RAG) pipeline specifically designed for querying sensitive nuclear plant security documentation. The system demonstrates how privacy-critical domains can leverage locally hosted AI infrastructure without relying on external APIs or cloud services.
The architecture uses ChromaDB as the vector database for efficient document storage and similarity search, paired with Ollama for local LLM inference. ChromaDB is an open-source vector database designed for embedding storage, semantic search, and retrieval workflows, making it a strong fit for RAG-based architectures. Its lightweight design, simple local setup, and ability to run fully offline allow us to keep embeddings and sensitive data on-device, which aligns well with local-first AI patterns.
During indexing, documents are first loaded from the documents directory and then split into overlapping chunks by the TextChunker. The chunking process uses a character-based approach, with a chunk size of 1500 characters and a 200-character overlap between consecutive chunks. The chunker attempts to break at sentence boundaries (looking for . , .\n, !\n, ?\n) to avoid cutting mid-sentence, and it uses the overlap to preserve context across chunk boundaries. Once chunked, each text chunk is sent to Ollama’s all-minilm:latest model via the LocalEmbedder.embed_text() method, which generates a dense vector embedding (a list of floats representing the semantic meaning). These embeddings, along with the original chunk text and metadata (source file, chunk index, etc.), are then stored in the ChromaDB database. This creates a searchable vector index where each chunk can be efficiently retrieved based on semantic similarity.
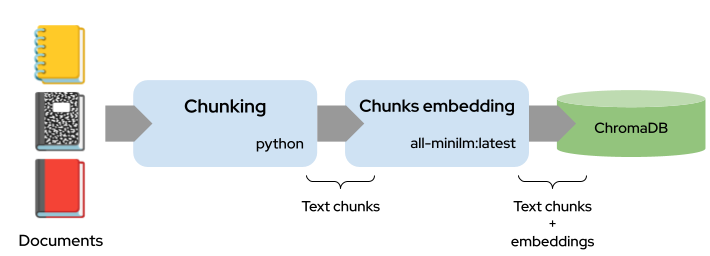
When you submit a query, the same all-minilm:latest model generates an embedding vector for your query text using the identical LocalEmbedder.embed_text() method. This query embedding is passed to ChromaDB, which performs a vector-similarity search by computing L2 distances between the query embedding and all stored chunk embeddings in its index. ChromaDB returns the top-k most similar chunks (default: 5) that have distances below the similarity threshold (1.5), sorted by relevance. These retrieved chunks are then used as context for the reasoning model (LFM2.5) to generate the final answer, ensuring the response is grounded in your actual documents.
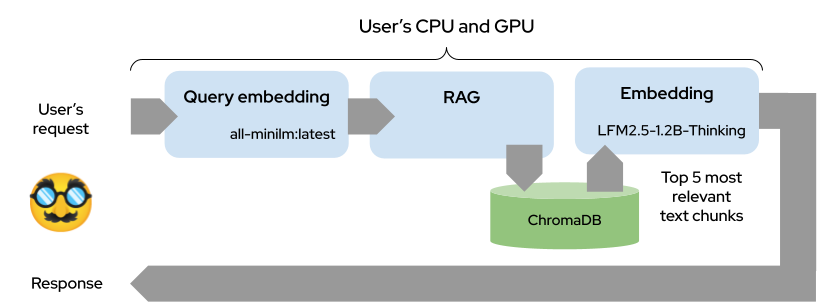
The use case centers on the (fictional!) Springfield Nuclear Facility’s security documentation encompasses both cybersecurity protocols (network segmentation, SCADA systems, access control) and physical security procedures (perimeter zones, biometric authentication, personnel screening). Documents are chunked into 1,500-character segments with 200-character overlap to preserve context, embedded into ChromaDB’s vector space, and retrieved using distance similarity search. The reasoning engine then synthesizes responses from the top-5 most relevant chunks, ensuring answers are grounded in actual security protocols rather than hallucinated content. This architecture guarantees data sovereignty, sub-second query latency, and the ability to operate in air-gapped environments critical requirements for nuclear facility operations.
The system provides a command-line interface for querying the nuclear plant security documentation. Here is a practical example demonstrating the RAG pipeline in action:
$ python run.py --query "Describe the biometric authentication requirements" ====================================================================== RESPONSE ====================================================================== Based on the retrieved context, biometric authentication is mandated for privileged accounts (e.g., requiring biometric verification alongside other factors like password/token) and is explicitly required for entry into restricted zones (e.g., Zone 3: "Biometric authentication (fingerprint and retinal scan) is required"). These requirements align with access control protocols emphasizing security for sensitive areas. Sources: nuclear_plant_cyber_security.md, nuclear_plant_physical_security.md
The system automatically classifies the query intent, retrieves relevant document chunks from the ChromaDB vector database, and synthesizes a coherent response grounded in the source material. The entire process completes in under 2 seconds on consumer hardware, with all processing occurring locally, no external API calls, no data transmission, and complete air-gap compatibility for classified environments.
Two questions may come up when discussing local SLM + RAG architectures: how much control we actually have over hallucinations, and how small the deployment footprint can realistically be.
On the control side, using SLMs within a RAG pipeline gives us more levers than a single large model. We are not using an LLM that just “knows everything” (and this is good). The SLM strongly relies on the retrieved context, which means we can enforce grounding in real documentation. If the system produces incorrect or unsupported answers, the fix is often in the pipeline rather than the model itself: adjusting retrieval parameters, improving chunking, or adding another SLM for verification steps that check whether responses are actually backed by retrieved sources. Because everything runs locally and modularly, debugging and tuning become practical engineering tasks instead of opaque prompt experimentation.
As for deployment boundaries, SLMs make local-first AI realistic today. Many models can run on desktops, laptops, or edge servers without requiring cloud infrastructure. Retrieval keeps the reasoning scope small, which allows smaller models to perform well without excessive hardware demands. Historically, what we call “large” quickly becomes standard and lightweight over time, and the same trend is already visible here. Watching how agentic architectures evolve will be key to understanding just how far local SLM deployments can go in the near future.

AI-generated tests can speed up React testing, but they also create hidden risks. Here’s what broke in a real app.re

Why the future of DX might come from the web platform itself, not more tools or frameworks.

A hands-on test of Claude Code Review across real PRs, breaking down what it flagged, what slipped through, and how the pipeline actually performs in practice.

CSS art once made frontend feel playful and accessible. Here’s why it faded as the web became more practical and prestige-driven.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

