It’s clear that an LLM capable of all human languages, possessing complete knowledge of Dante Alighieri, and expert at writing Haskell code is often unnecessary. Such comprehensive power isn’t required to decide which API to call for a weather check or to format a table showing the average temperature for the next few days in Salerno, Italy.

For many developers, the issue goes further than overkill. In products or organizations where code, documents, or operational data are confidential, sending prompts and context to Claude, GPT, or similar services is simply not an option. Internet access may be restricted, data may not be allowed to leave the network, and “just use a hosted LLM” becomes a non-starter.
This creates an interesting problem: teams want to use AI, but cannot use AI in the way it is usually packaged and sold.
Small language models offer a way out. Because they can run locally or on modest on-premise servers, they make it possible to build agentic systems that are private by design – handling reasoning, retrieval, and decision-making without leaking data to the cloud. In this sense, this article is about how to use AI when the usual way of using AI is off the table.
The Replay is a weekly newsletter for dev and engineering leaders.
Delivered once a week, it's your curated guide to the most important conversations around frontend dev, emerging AI tools, and the state of modern software.
Agentic AI systems are often presented as a single large language model calling tools in a loop. While this approach is easy to prototype, it quickly breaks down in real-world settings: privacy constraints, cost, latency, and reliability all become major blockers.
Recent research on SLMs suggests a different path. Instead of scaling intelligence through larger and more centralized models, we can build agentic systems composed of multiple specialized SLMs, running locally by default and escalating to the cloud only when expressivity, not reasoning, is required.
In this article, we design a privacy-first agentic architecture directly informed by recent empirical evaluation of SLMs, particularly the ThinkSLM: Towards Reasoning in Small Language Models (EMNLP 2025). Rather than choosing models based on popularity or intuition, we derive architectural roles from measured capabilities.
The promise of SLMs is not that they are “smaller LLMs,” but that they exhibit different capability tradeoffs. The challenge is understanding which tasks they handle well and which they do not.
The ThinkSLM paper addresses this directly by evaluating 72 small language models across 17 reasoning benchmarks, spanning logical reasoning, arithmetic, commonsense, and symbolic tasks. Importantly, the results show that reasoning ability in SLMs is not binary, nor strictly determined by parameter count. Instead, performance depends heavily on model family, training strategy, and inference-time techniques.
This makes SLMs especially interesting for agentic systems, where different components require different kinds of intelligence.
Before designing the architecture, we can extract four practical conclusions from ThinkSLM.
ThinkSLM shows that several models in the 1–3B parameter range, particularly Phi-family models, achieve strong multi-step reasoning performance relative to their size. These models consistently outperform both smaller sub-1B models and many similarly sized alternatives on structured reasoning tasks.
A key finding is that test-time scaling – multiple generations, self-consistency, majority voting – significantly improves reasoning accuracy in SLMs. In some cases, this closes much of the gap with much larger models.
Smaller SLMs consistently underperform on reasoning benchmarks but remain effective at classification-oriented tasks, such as intent detection and filtering.
Tasks that limit the hypothesis space – such as retrieval-augmented generation (RAG) – do not benefit from large generative capacity. In these settings, smaller models remain stable and reliable, especially when hallucination must be minimized.
These findings give us a clear foundation to derive an architecture.
An additional, derived principle: reasoning, retrieval, and expression are different problems. One of the most important implications of ThinkSLM is that reasoning is not equivalent to fluent text generation. Many agentic systems conflate the two by using a single large model.
Instead, the evidence supports a separation of concerns:
This principle underpins the rest of the design: at a high level, the system consists of
Crucially, private documents never leave the device.
The table below breaks down the core components of the system, their responsibilities, and why each design choice works in practice.
| Component | Primary role | Size | Why this works | Runs where |
|---|---|---|---|---|
| Agent manager | Orchestrate models, track confidence, apply test-time scaling | n/a | Implements test-time compute and escalation logic | Local (classic code, e.g., Python) |
| Intent detection | Classify user intent, extract entities, and route requests | < 1B | Sub-1B models underperform on multi-step reasoning but remain strong at classification and decision boundaries | Local (on-device) |
| Safety & policy | Detect unsafe actions, PII leakage, and prompt injection | < 1B | Classification tasks don’t benefit from reasoning-heavy models; smaller models are more auditable and deterministic | Local (on-device) |
| Planner/reasoning | Decompose tasks into executable steps and coordinate actions | 1–3B | Phi-class SLMs show strong reasoning relative to size; test-time scaling improves reliability | Local (on-device) |
| RAG (private docs) | Synthesize answers from retrieved private documents | 1–2B | Constrained generation reduces hypothesis space, allowing smaller models to remain effective | Local (on-prem) |
| Vector database | Store embeddings of private documents for retrieval | n/a | Keeps documents local and enables privacy by architectural design | Local (on-prem) |
| Tool/action | Produce structured API calls, file operations, and system actions | 1–3B | Instruction-following stability matters more than expressive generation; quantization preserves reasoning | Local (on-device) |
| Cloud LLM (optional) | Rewrite outputs for tone, clarity, and expressivity | LLM | Large models excel at stylistic transformation, not privacy-critical reasoning | Cloud (sanitized input only) |
In this architecture, the cloud is used only after reasoning is complete, and only on sanitized outputs.
This architecture works in practice because it ensures privacy by design through architecturally enforced data locality: models and the data they manipulate are on the internal network. Furthermore, it achieves scalability thanks to the fact that models of this size can be deployed on cheaper (in terms of SKU price and power) GPUs. Another relevant aspect of SLMs is their auditability: with respect to LLMs, they are less “creative” and deterministic, which in many contexts is a plus. And, last but not least, it offers cost efficiency as most requests never reach the cloud LLM APIs.
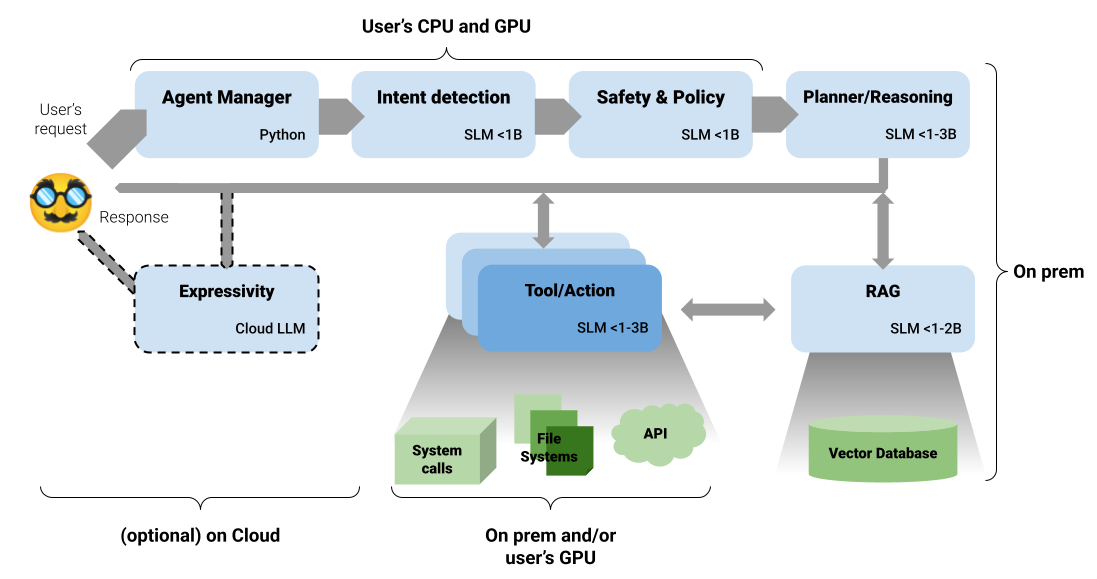
In the diagram above, describe the whole system deployment with the details of each component. The last stage, the execution of the LLM in the cloud part, is used for expressivity and is optional: not every use case needs natural language responses (feeding data to a dashboard, for example).
Consider an enterprise operating under strict data locality and regulatory constraints (e.g., GDPR), where internal documents, logs, and source code are not allowed to leave the corporate network. Teams want AI-assisted support for internal workflows – such as querying private documentation, triaging incidents, and generating structured remediation steps – but sending prompts or context to a hosted LLM is prohibited by policy and compliance requirements.
In this setting, most requests require reliable intent classification, multi-step reasoning, and retrieval over confidential data – not open-ended text generation. The architecture described above allows these capabilities to run entirely on-premise using specialized SLMs: smaller models handle intent detection and policy enforcement, a 1–3B reasoning model performs task decomposition, and a local RAG component synthesizes answers from private documents stored in an internal vector database. Cloud LLMs, if used at all, are invoked only after sensitive context has been removed, and solely for optional output rewriting.
The key lesson from ThinkSLM is not that small language models are merely “good enough,” but that reasoning, classification, retrieval, and expression are fundamentally separable concerns. Once separated, these capabilities can be handled by models that comfortably run on commodity GPUs, making on-premise or fully local deployment not just feasible, but practical.
This shift matters most in the very scenarios where large, hosted LLMs fall apart: confidential products, restricted networks, and systems where data cannot leave the boundary. In these environments, small language models are not a compromise forced by constraints – they are an architectural advantage.
The future of agentic AI is therefore not a single, all-knowing model reasoning over everything. It has many specialized SLMs, orchestrated intelligently, operating close to the data. For teams that want to use AI but cannot use it in the usual way, this approach turns a limitation into a viable design pattern.

Within roughly the same six-month window, Anthropic shipped Agent Teams for Claude Code, OpenAI published Swarm and the production-ready Agents […]

Compare the top AI development tools and models of March 2026. View updated rankings, feature breakdowns, and find the best fit for you.

Discover what’s new in The Replay, LogRocket’s newsletter for dev and engineering leaders, in the March 11th issue.

Buying AI tools isn’t enough. Engineering teams need AI literacy programs to unlock real productivity gains and avoid uneven adoption.
Hey there, want to help make our blog better?
Join LogRocket’s Content Advisory Board. You’ll help inform the type of content we create and get access to exclusive meetups, social accreditation, and swag.
Sign up now

